ASTRA-sim Tutorial @ MLSys 2022
Overview
In this tutorial, we will educate the research community about the challenges in the emerging domain of distributed training, demonstrate the capabilities of ASTRA-sim with examples and discuss ongoing development efforts.
Date/Location
- Aug 31, 2022, 1-5 PM PDT (4-8 PM EDT)
- Santa Clara, CA, USA
- Santa Clara Convention Center, Room 203
Description
Modern Deep Learning systems heavily rely on distributed training over customized high-performance accelerator (e.g., TPU, GPU)-based hardware platforms connected via high-performance interconnects (e.g., NVLink). Examples today include NVIDIA’s DGX-2, Google’s Cloud TPU and Facebook’s Zion. Deep Neural Network (DNN) training involves a complex interplay between the DNN model architecture, parallelization strategy, scheduling strategy, collective communication algorithm, network topology, and the accelerator endpoint. Collective communications (e.g., All-Reduce, All-to-All, Reduce-Scatter, All-Gather) are initiated at different phases for different parallelism approaches — and play a crucial role in overall runtime, if not hidden efficiently behind compute. This problem becomes paramount as recent models for NLP such as GPT-3 and Recommendations such as DLRM have billions to trillions of parameters and need to be scaled across tens to hundreds to thousands of accelerator nodes. As innovation in AI/ML models continues to grow at an accelerated rate, there is a need for a comprehensive methodology to understand and navigate this complex design-space to (i) architect future platforms and (ii) develop novel parallelism schemes to support efficient training of future DNN models.
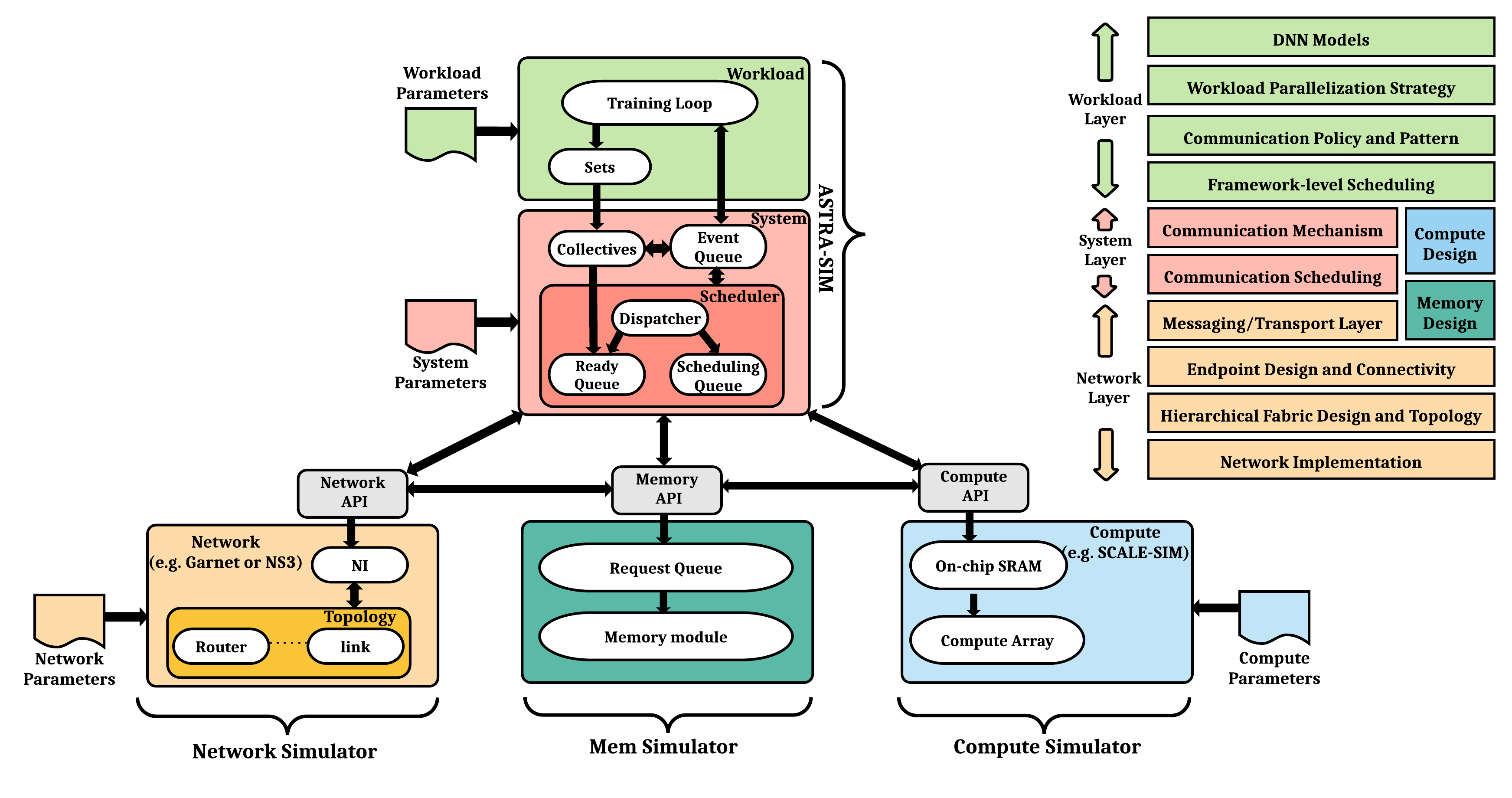
As an ongoing collaboration between Intel, Facebook and Georgia Tech, we have been jointly developing a detailed cycle-accurate distributed training simulator called ASTRA-sim. ASTRA-sim models the co-design space described above and schedules the compute-communication interactions from distributed training over plug-and-play compute and network simulators. It enables a systematic study of bottlenecks at the software and hardware level for scaling training. It also enables end-to-end design-space exploration for running large DNN models over future training platforms. Currently, ASTRA-sim supports two compute models (roofline and SCALE-sim, a Google TPU-like simulator) and several network models (analytical network, Garnet from gem5, and NS3) to go from simple analytical to detailed cycle-accurate simulation of large-scale training platforms. In this tutorial, we will educate the research community about the challenges in the emerging domain of distributed training, demonstrate the capabilities of ASTRA-sim with examples and discuss ongoing development efforts.
Target Audience
The tutorial targets students, faculty, and researchers who want to
- learn cycle-accurate distributed training simulator
- study performance implications of workloads, systems, and network configurations
Organizers
 |
Tushar Krishna (Georgia Tech) Email Website LinkedIn Tushar Krishna is an Associate Professor in the School of ECE at Georgia Tech since 2015. He also holds the ON Semiconductor Endowed Junior Professorship. He has a Ph.D. in Electrical Engineering and Computer Science from MIT (2014), a M.S.E in Electrical Engineering from Princeton University (2009), and a B.Tech in Electrical Engineering from the Indian Institute of Technology (IIT) Delhi (2007). Dr. Krishna’s research spans the computing stack: from circuits/physical design to microarchitecture to system software. His key focus area is in architecting the interconnection networks and communication protocols for efficient data movement within computer systems, both on-chip and in the cloud. |
 |
Srinivas Sridharan (Meta) Srinivas Sridharan is a Research Scientist at Meta/Facebook and works on communication libraries, networking, and simulation for Facebook's AI Infrastructure. Before joining Facebook, he was a Research Scientist at Intel Labs. At Intel, he led the development of Intel's Machine Learning Scaling Library (MLSL), a library to accelerate AI/deep-learning operations on Intel platforms, which is an Intel product today. He received multiple awards during his tenure at Intel – the Intel Labs Gordy Award, Intel SSG/DPD Divisional Recognition Award, Intel DCG Divisional Recognition Award (twice) and the Intel TCAR Award. He received his PhD in Computer Science and Engineering from the University of Notre Dame in 2010. |
 |
Saeed Rashidi (Georgia Tech) Email LinkedIn Saeed Rashidi received his BS from Shiraz University in 2015, and his MS from Sharif University of Technology in 2017, both in Computer Engineering. He joined Georgia Tech in Spring 2019 to start his PhD in Electrical & Computer Engineering. His research interests are DNN Training/Inference Accelerators, Scalable Training HW/SW co-design, ML algorithms and Domain-Specific accelerator design in general. |
 |
William Won (Georgia Tech) Email Website LinkedIn William (Jonghoon) Won is a Ph.D. student in Computer Science at Georgia Tech. He's studying systems and algorithms for deep learning. His research interests include: DNN training software-hardware-network co-design, Distributed DNN systems, DNN accelerator designs, Machine learning algorithms, and Neural architecture search. |
 |
Taekyung Heo (Georgia Tech) Email Website LinkedIn Taekyung Heo is a postdoctoral researcher at Georgia Tech and a research advisor at Meta. He received a Ph.D. in Computer Science from KAIST (2022), an M.S. from KAIST (2016), and a B.S. from Sungkyunkwan University (2014). During his Ph.D. studies, he focused on co-designing HW and SW for terabyte-scale memory systems. After finishing his Ph.D., Taekyung joined the Synergy Lab to extend his research area to machine learning. Currently, he is actively engaged in optimizing the performance of distributed training systems by addressing various challenges in the areas of memory systems, network-on-chip, and system performance modeling. |
Schedule
| Time (PDT) | Time (EDT) | Agenda | Presenter | Resources |
|---|---|---|---|---|
| 1:00 PM | 4:00 PM | Introduction to Distributed DL Training | Tushar | Slide Video |
| Training Platforms | ||||
| Parallelism Strategies | ||||
| Collective Communication | ||||
| 2:00 PM | 5:00 PM | Training Systems Challenges: An Industry Perspective from Meta |
Srinivas | |
| 2:20 PM | 5:20 PM | ASTRA-sim | Saeed | Slide Video |
| Overview | ||||
| Workload Generator | ||||
| Workload Layer | ||||
| System Layer | ||||
| Network Layer | ||||
| 3:30 PM | 6:30 PM | Coffee Break | ||
| 4:00 PM | 7:00 PM | Demo and Exercises | ||
| Exercise 1: Getting Started with ASTRA-sim | William | Slide Video | ||
| Exercise 2: Comparing Collectives | William | Slide Video | ||
| Exercise 3: Comparing Systems | William | Slide Video | ||
| Exercise 4: Implementing a new Training Loop | Taekyung | Slide Video | ||
| 4:50 PM | 7:50 PM | Extensions and Future Development | Taekyung | Slide Video |