ASTRA-sim2.0 Tutorial @ HotI 2024
Overview
In this tutorial, we will educate the research community about the challenges in the emerging domain of distributed machine learning, demonstrate the capabilities of ASTRA-sim2.0 with examples and discuss ongoing development efforts.
Date/Location
- Aug 23, 2024, 3–5 pm PDT (6–8 pm EDT)
- Fully virtual event Info
Recording of the Tutorial
Description
As Artificial Intelligence (AI) models are scaling at an unprecedented rate, Machine Learning (ML) execution heavily relies on Distributed ML over customized neural accelerator (e.g., GPU or TPU)-based High-Performance Computing (HPC) platforms connected via high-speed interconnects (e.g., NVLinks). Examples today include NVIDIA’s HGX, Google’s Cloud TPU, and Meta’s Research Supercluster. Distributed Deep Neural Network (DNN) execution involves a complex interplay between the DNN model architecture, parallelization strategy, scheduling strategy, collective communication algorithm, network topology, remote memory accesses, and the accelerator endpoint.
Collective communications (e.g., All-Reduce, Reduce-Scatter, All-Gather, All-to-All) are initiated at different phases for different parallelism approaches and play a crucial role in overall runtime if not hidden efficiently behind computation. This problem becomes paramount as recent Large Language Models (LLMs), such as GPT-3, and Recommendation models, such as DLRM, have billions to trillions of parameters and need to be scaled across tens of thousands of accelerator nodes. As innovation in AI/ML models continues to grow at an accelerated rate, there is a need for a comprehensive methodology to understand and navigate this complex intertwined co-design space to (i) architect future platforms, (ii) develop novel parallelism schemes to support efficient training of future DNN models, and (iii) develop novel fabrics for AI systems.
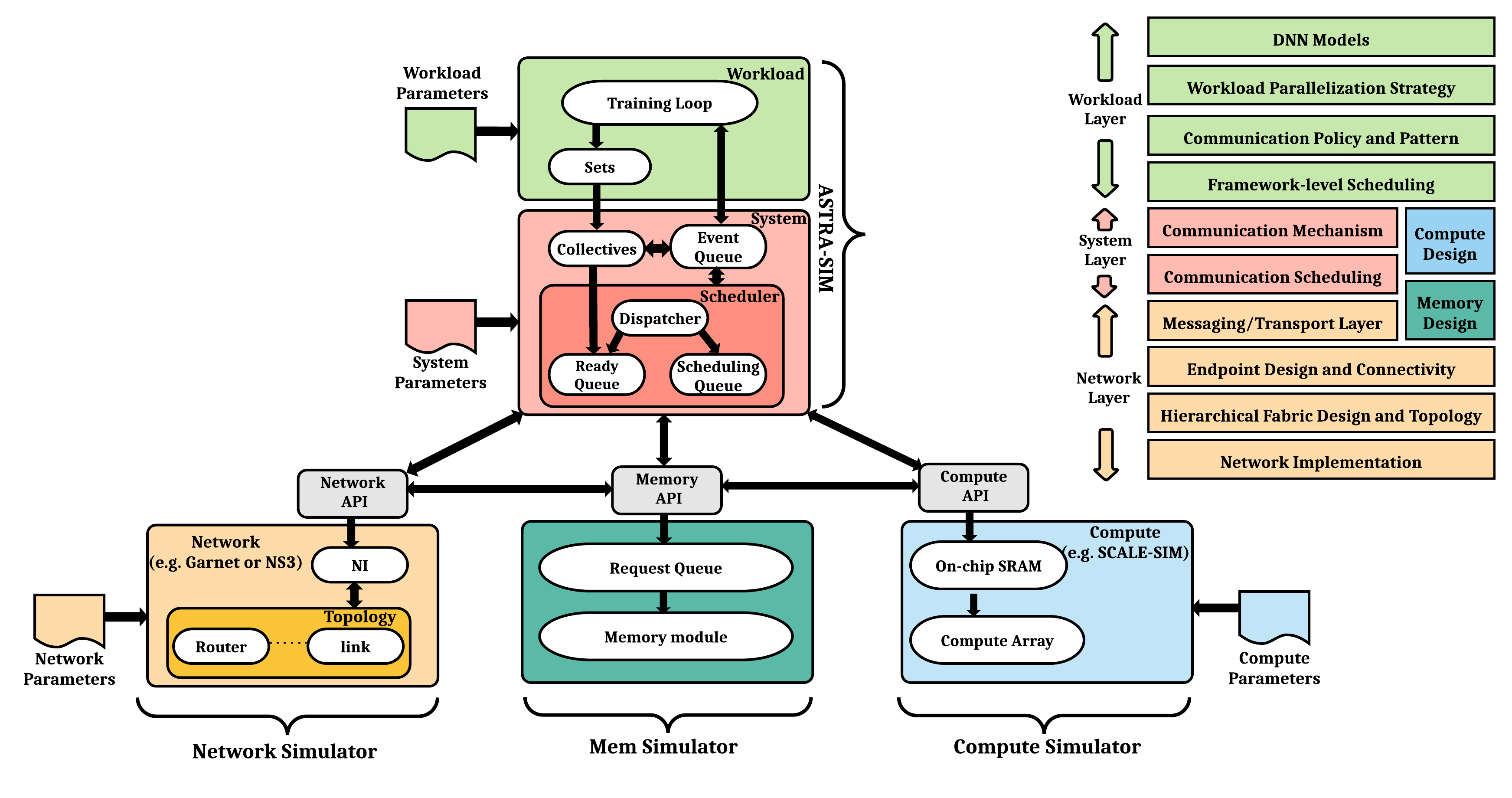
As an ongoing collaboration between Georgia Tech and several companies (Intel, Meta, AMD, NVIDIA, and HPE), we have been jointly developing a detailed cycle-accurate distributed AI simulator called ASTRA-sim. ASTRA-sim models the co- design space of distributed ML described above and schedules the compute-communication interactions over plug-and-play computation, network, and remote memory simulators. It enables a systematic study of bottleneck detection and futuristic system evaluation at the software and hardware levels for scaling distributed ML. ASTRA-sim leverages the MLCommons Chakra format to describe arbitrary distributed ML workloads. It uses a Google TPU-like simulator as its computation model and provides a suite of network models (analytical network, Garnet, and ns-3) for the choice of simulation speed and fidelity.
Target Audience
Any researcher with the interest in full-stack, large-scale AI/ML simulation.
Organizers
 |
Tushar Krishna (Georgia Tech) Email Website LinkedIn Tushar Krishna is an Associate Professor in the School of Electrical and Computer Engineering at Georgia Tech. He is currently also a Visiting Associate Professor at the Department of Electrical Engineering and Computer Science at MIT. He has a Ph.D. in Electrical Engineering and Computer Science from MIT (2014), a M.S.E in Electrical Engineering from Princeton University (2009), and a B.Tech in Electrical Engineering from the Indian Institute of Technology (IIT) Delhi (2007). Before joining Georgia Tech in 2015, Dr. Krishna spent a year as a researcher at the VSSAD group at Intel, Massachusetts. Dr. Krishna's research spans computer architecture, interconnection networks, networks-on- chip (NoC), and AI/ML accelerator systems, with a focus on optimizing data movement in modern computing platforms. His research is funded via multiple awards from NSF, DARPA, IARPA, SRC (including JUMP2.0), Department of Energy, Intel, Google, Meta/Facebook, Qualcomm and TSMC. |
 |
William Won (Will) (Georgia Tech) Email Website LinkedIn William Won is a Ph.D. student in the College of Computing at Georgia Tech. He received M.S. in Computer Science at Georgia Tech in 2022, and B.S. in Computer Science and Enginnering at Seoul National University in 2019. His research interests include training and inference of distributed machine learning, simulation of distributed machine learning workloads, collective communication optimizations, and machine learning algorithms. |
Schedule
| Time (PDT) | Time (EDT) | Agenda | Presenter | Resources |
|---|---|---|---|---|
| 3:00 pm | 6:00 pm | Introduction to Distributed ML | Tushar | Slide |
| 3:30 pm | 6:30 pm | Overview of Chakra and ASTRA-sim | Tushar | Slide |
| 3:45 pm | 6:45 pm | Deeper Dive into Chakra and ASTRA-sim | Will | |
| Workload Layer | Slide | |||
| System Layer | Slide | |||
| Network Layer | Slide | |||
| 4:35 pm | 7:35 | Demo | Will | Slide |
| 4:45 pm | 7:45 | Closing Remarks | Tushar | Slide |
Additional Resources
Installation
MLCommons Chakra Working Group
ASTRA-sim2.0 Paper
William Won, Taekyung Heo, Saeed Rashidi, Srinivas Sridharan, Sudarshan Srinivasan, and Tushar Krishna, “ASTRA-sim2.0: Modeling Hierarchical Networks and Disaggregated Systems for Large-model Training at Scale,” In Proc. of the IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2023.
Chakra Paper
Srinivas Sridharan, Taekyung Heo, Louis Feng, Zhaodong Wang, Matt Bergeron, Wenyin Fu, Shengbao Zheng, Brian Coutinho, Saeed Rashidi, Changhai Man, and Tushar Krishna, “Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces,” In arXiv:2305.14516 [cs.LG], 2023.