ASTRA-sim: Enabling Software-Hardware Co-Design Exploration for Distributed Machine Learning Platforms
![]()
Overview
Date/Location
- Jun 27, 2026 (Saturday: full-day)
- Raleigh Convention Center Info
- This tutorial will also be delivered online for remote attendees Remote Info
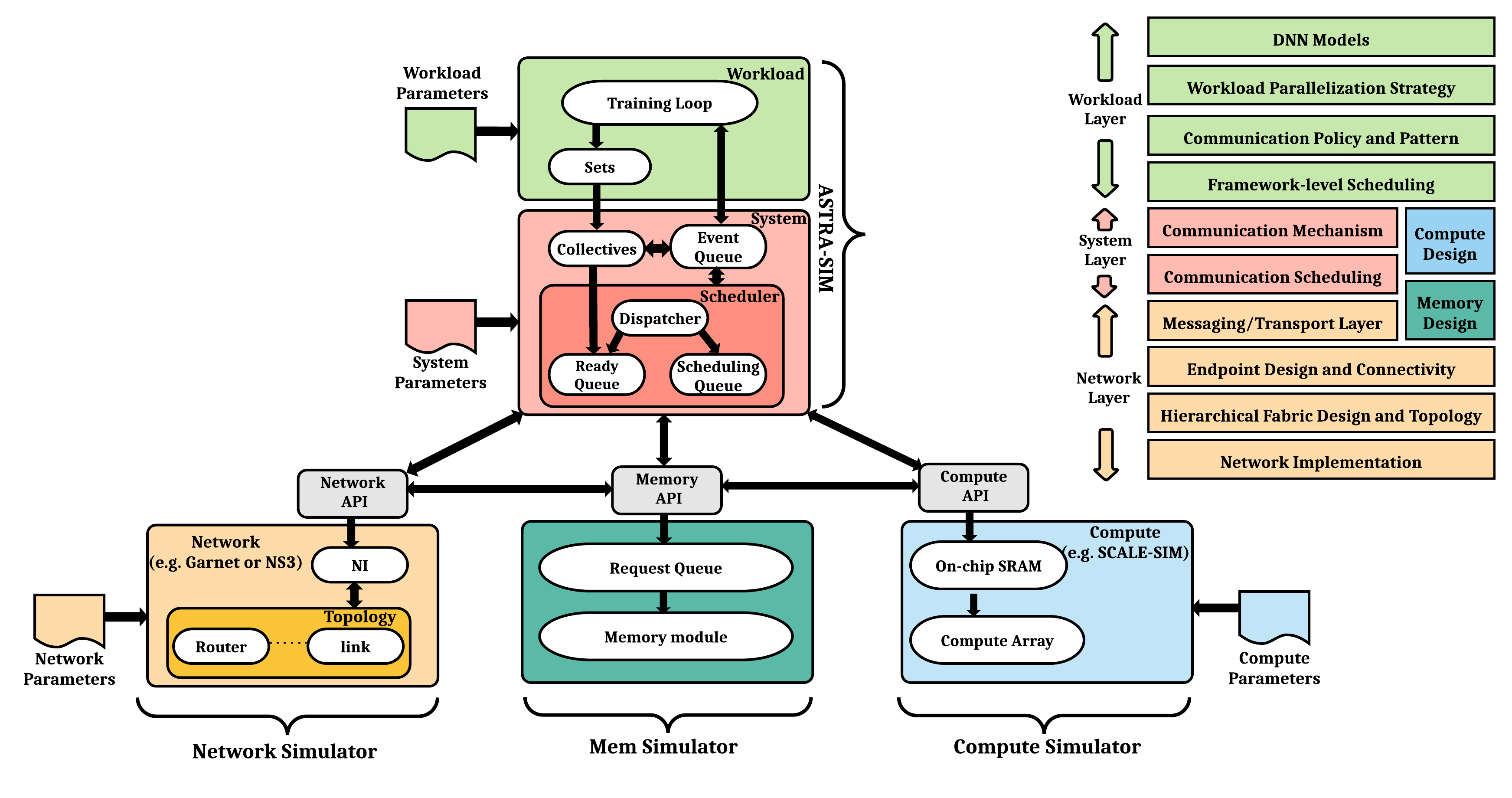
The ASTRA-sim tutorials educate the research community about the challenges in the emerging domain of distributed machine learning, demonstrate the capabilities of ASTRA-sim with examples and discuss ongoing development efforts.
NEW – In this tutorial for ISCA 2026, we will (1) introduce the latest features added to the ASTRA-sim framework, and (2) have invited presentations on the usage of ASTRA-sim in various use cases.
Schedule
Tutorial video recording. Note: We will split this into per-session video in the future.
Morning Session
| Time (EDT) | Topic | Presenter | Resources |
|---|---|---|---|
| [ Introduction ] | |||
| 8:00 am | Introduction to Distributed AI/ML | Tushar Krishna (Georgia Tech / InfraVana) |
Slide |
| [ End-to-End Simulation ] | |||
| 8:15 am | Workload and System Layer | Will Won (AMD) |
Slide |
| 8:35 am | Chakra Trace Generation | Changhai Man (Georgia Tech) |
Slide |
| 8:50 am | Network Layer and ns-3 | Jinsun Yoo (Georgia Tech) |
Slide |
| 9:10 am | Extending ASTRA-sim with HTSim for Ultra Ethernet Simulation | Veerasenareddy Burru (Marvell) |
Slide |
| [ Infrastructure ] | |||
| 9:30 am | InfraGraph: Vendor-Neutral Infrastructure Topology for AI/HPC | Harsh Sikhwal (Keysight) |
Slide |
| 10:00 am | [Coffee Break] | ||
| 10:30 am | [ Fine-Grained Communication and GPU Modeling ] | ||
| Customized Collectives Algorithms with MSCCLPP | Ruchi Shah (AMD) |
||
| Detailed GPU Model in System Layer | Tuan Ta (AMD) |
||
| Inter-GPU Communication Protocols & Synchronization | Moumita Dey (AMD) |
Afternoon Session
| Time (EDT) | Topic | Presenter | Resources |
|---|---|---|---|
| [ Keynote ] | |||
| 1:40 pm | Lessons from a Quarter-Century of Computer Architecture Simulation | Brad Beckmann (AMD) |
Slide |
| [ ASTRA-sim Use Cases ] | |||
| 2:10 pm | Beyond Communication Modeling: Extending ASTRA-sim for End-to-End AI Infrastructure Design and Evaluation | Puneet Sharma (HPE) |
|
| 2:30 pm | ASTRA-sim-service: A Composable Simulation Interface for AI Infrastructure Co-Design Across Workloads and Fidelity Tiers | Harsh Sikhwal (Keysight) |
Slide |
| 2:50 pm | Hespas: Multi-Fidelity Simulation of StableHLO-ML Workloads with ASTRA-sim | Abubakr Nada (imec) |
Slide |
| 3:10 pm | A Co-Design Framework for Heterogeneous Multi-Stage LLM Inference using ASTRA-SIM | Abhimanyu Bambhaniya (Georgia Tech/InfraVana) |
|
| 3:30 pm | [Coffee Break] | ||
| [ ASTRA-sim New Features ] | |||
| 4:00 pm | Enabling Memory Tiering in ASTRA-sim with Extended Chakra Traces | Ulf Hanebutte and Nikhil Stephen (Marvell), Shuting Du (Purdue) |
Slide |
| 4:20 pm | Enabling Energy Efficiency for Distributed Machine Learning | Tanvir Ahmed Khan and Tawhid Bhuiyan (Columbia) |
Slide |
| 4:40 pm | Modeling Multi-tenant Scheduling in ML Clusters using Astra-sim | Shawn Chen (CMU) |
Slide |
Organizers
- Brad Beckmann, Tuan Ta, Will Won (AMD Research and Advanced Development)
- Tushar Krishna, Jinsun Yoo (Georgia Institute of Technology)
Presenters
| [ Morning Session ] | |
 |
Introduction to Distributed AI/ML Tushar Krishna (Georgia Tech / InfraVana) Email Website LinkedIn Bio: Tushar Krishna is an Associate Professor in the School of Electrical and Computer Engineering at Georgia Tech. His research spans computer architecture, interconnection networks, networks-on-chip (NoC), and AI/ML accelerator systems, with a focus on optimizing data movement in modern computing platforms. He is also a co-chair of the Chakra Working Group within MLCommons. He is also co-founder and CEO of InfraVana. |
 |
Workload and System Layer Will Won (AMD) Email LinkedIn Bio: Will Won is a postdoctoral research associate at AMD Research and Advanced Development. His current focus is on software-hardware optimizations for collective communications. |
 |
Chakra Trace Generation Changhai Man (Georgia Tech) LinkedIn Abstract: This tutorial introduces engineering workflows for generating Chakra Execution Trace (ET) files before running workloads on large GPU clusters. This enables fast Chakra trace generation without expensive real-system trace collection, which can require significant compute resources, engineering effort, and time. We will cover two approaches: 1) STAGE, which synthesizes Chakra traces from high-level symbolic tensor and workload descriptions, and 2) Flint, which reuses the framework execution path to generate workload graphs from model code before hardware execution. Together, these tools help users create scalable and configurable distributed LLM workload traces without relying on large-scale system access. The generated traces capture compute, memory, communication, and dependency behavior, and can be used by ASTRA-sim and other downstream tools for performance modeling, parallel strategy exploration, and system design-space studies. Bio: Changhai Man is a PhD student at Georgia Tech, working with Prof. Tushar Krishna. His work focuses on workload characterization and performance modeling for distributed machine learning workloads, with an emphasis on system-level optimization. He is also a contributor to ASTRA-sim and Chakra. |
 |
Network Layer and ns-3 Jinsun Yoo (Georgia Tech) Email LinkedIn Bio: Jinsun Yoo is a fifth-year Ph.D. student at Georgia Tech, advised by Tushar Krishna and Kishore Ramachandran. His research focus is on modelling the transport and collective algorithm of distributed AI communication. |
 |
Extending ASTRA-sim with HTSim for Ultra Ethernet Simulation Veerasenareddy Burru (Marvell) LinkedIn Abstract: Ultra Ethernet (UEC) is emerging as the transport for large-scale AI fabrics, with new transport semantics, multipath load balancing, and congestion control tailored to collective communication. HTSim is the UEC working group's reference packet-level simulator for these mechanisms; ASTRA-sim is a widely used distributed-ML simulator that captures how collective libraries decompose AI workloads into wire-level traffic. We present work that integrates HTSim as a new network backend for ASTRA-sim, driven by Chakra execution traces — enabling trace-driven simulation of UEC transports under realistic AI workloads. The integration supports a scenario-driven benchmarking flow aligned with the emerging UEC PD8001 specification. We share results to highlight the value of full-stack UEC simulation and invite community feedback on this timely direction. Bio: Veerasenareddy Burru is a Principal Engineer at Marvell, where he works on HW/SW co-design, datapath acceleration, and networking and systems solutions built around Marvell's custom hardware and software. His work focuses on datacenter and AI-scale networking, and on end-to-end optimization of LLM applications — particularly extending the GPU memory tier architecture and networking acceleration using Marvell accelerators alongside GPUs. |
 |
InfraGraph: Vendor-Neutral Infrastructure Topology for AI/HPC Harsh Sikhwal (Keysight) LinkedIn Abstract: Modern AI and HPC systems are becoming increasingly complex, with heterogeneous devices, hierarchical fabrics, and topology-sensitive communication patterns. However, infrastructure descriptions remain fragmented across simulation, visualization, and deployment workflows, resulting in duplicated effort and limited interoperability. InfraGraph introduces a vendor-neutral schema and API that models infrastructure as graphs, providing a common abstraction for devices, components, links, and connectivity. Declarative descriptions are expanded into explicit graph representations that support querying, annotation, and integration with downstream tools. InfraGraph enables reusable and interoperable infrastructure workflows and facilitates topology-aware studies across AI and HPC ecosystems. Bio: Harsh Sikhwal is a Senior Software Engineer at Keysight Technologies, working on AI infrastructure, system architecture, and performance engineering for large-scale AI/ML systems. He leads the development of InfraGraph and the ASTRA-sim-service, enabling reusable workflows for infrastructure modelling, simulation, and AI/ML system architecture research. His work focuses on simulation and hardware/software emulation of AI/ML workloads, collective communication, and hardware/software co-design for next-generation AI datacentres. He has contributed to SONiC, Open Traffic Generator (OTG), and network testing frameworks, and is also active in applied AI systems, including RAG- and MCP-based architectures. His interests include high-performance computing, infrastructure modelling, and AI system design. |
   |
Fine-Grained Communication and GPU Modeling Ruchi Shah (AMD) LinkedIn Tuan Ta (AMD) Email LinkedIn Moumita Dey (AMD) LinkedIn Abstract: Collective communication is a key performance bottleneck in distributed machine learning, affecting both training throughput and inference latency. Modeling performance of collective communication kernels is key to enable design space exploration for future networking architectures, software–hardware co-design of collective and network architecture, and performance projection for future hardware. This talk introduces AMD's recent contributions to AstraSim to enable high-fidelity, fast, and flexible modeling of collective communication kernels running on GPUs. This talk has three parts. Part 1 (Customized Collectives Algorithms with MSCCLPP): This part provides background information on MSCCLPP, an open-source project contributed by Microsoft that enables designing customized collective algorithms through explicit, programmable communication schedules. Unlike traditional libraries that rely on fixed, topology-agnostic designs, this approach provides fine-grained control over data movement, synchronization, and execution across heterogeneous GPU systems. By enabling multi-peer concurrency, operation fusion, and topology-aware optimizations, it allows developers to build efficient, workload-specific collectives for next-generation scale-up and scale-out systems. MSCCLPP generates high-level descriptions of collective communication kernels as inputs to AstraSim. Part 2 (Detailed GPU Model in System Layer): We then delve into detailed GPU resource modeling, outlining how MSCCLPP operations are broken into wavefront-level instructions, how workgroups are mapped to compute units, and how each compute unit generates memory and network requests from its active wavefronts. This modeling connects high-level descriptions of collective communication kernels to the concrete behavior of GPU execution resources, so users of the simulator can reason about contention, overlap, and bottlenecks that emerge when mapping collective kernels to GPU microarchitectures. Part 3 (Inter-GPU Communication Protocols & Synchronization): Finally, we examine the synchronization control path that coordinates inter-GPU data transfers—an often-overlooked source of overhead with outsized impact. We compare common communication protocols (Simple, LL, LL128), explain the bandwidth–latency trade-offs that govern their performance across message sizes, and show how AstraSim captures the protocol-specific handling of synchronization flags and control-path costs. Accurately modeling this control path is essential for drawing correct system design conclusions. By unifying programmable collective design, resource-accurate GPU modeling, and faithful control-path simulation, the tutorial equips practitioners and researchers to co-design workload-specific collectives for next-generation distributed ML systems. Bio: Ruchi Shah is a Member of Technical Staff at AMD Research and Advanced Development, where she focuses on software-hardware co-design of high-performance collective algorithms for next-generation scale-up and scale-out systems. Her research interests include scale-up/scale-out networks, high-performance computing, collective communication optimization, and parallel and distributed AI/ML algorithms. She received her Ph.D. in Computer Science from University of Houston in 2022. Bio: Tuan Ta is a Member of Technical Staff at AMD Research and Advanced Development, where he focuses on performance modeling of large-scale GPU systems, in-network computing solutions, and novel network and system architectures for emerging interconnect technologies. Before joining AMD, he worked on CPU architecture design at Tenstorrent. He received his Ph.D. in Electrical and Computer Engineering from Cornell University in 2023. Bio: Moumita Dey is a Member of Technical Staff at AMD Research and Advanced Development, where she works on optimizing data movement for communication collectives using hardware-software co-design for next-generation datacenter GPU networking systems. She received her Ph.D. in Electrical and Computer Engineering from Georgia Tech in 2022. |
| [ Afternoon Session ] | |
 |
Lessons from a Quarter-Century of Computer Architecture Simulation Brad Beckmann (AMD) Email LinkedIn Bio: Brad Beckmann is an AMD Fellow and member of the AMD Research and Advanced Development group. Brad leads a team of researcher pursuing next-generation hardware and software technologies for scale-up/scale-out GPU networking. Brad joined AMD in 2007 and has led projects innovating in GPU memory consistency models, GPU cache coherence, simulation, and networking. He also co-led the initial development and release of the gem5 simulator in 2011. He has published over 40 conference and journal papers and co-authored over 60 granted patents. Brad has a PhD in Computer Science from University of Wisconsin-Madison. |
 |
Beyond Communication Modeling: Extending ASTRA-sim for End-to-End AI Infrastructure Design and Evaluation Puneet Sharma (HPE) LinkedIn Abstract: ASTRA-sim has become a widely used framework for modeling distributed AI workloads and communication behavior. As AI systems continue to grow in scale and complexity, there is increasing interest in extending ASTRA-sim beyond communication modeling to support broader AI infrastructure design and evaluation. This talk will highlight emerging directions in the ASTRA-sim ecosystem, including integration with complementary simulation frameworks, infrastructure validation and stress testing, and simulation-driven capacity planning. Through these examples, we will illustrate how ASTRA-sim can serve as a foundation for end-to-end AI systems research, enabling exploration and co-design across compute, memory, storage, and network resources. Bio: Dr. Puneet Sharma is an HPE Fellow, Vice President, and Director of the Networking and Distributed Systems Lab at HPE Labs, leading research in Edge-to-Cloud-to-Exascale Infrastructure, Multi-Cloud Resource Orchestration, AI for Infrastructure, 5G/WiFi, and Security. Since joining HP Labs in 1998 after earning his Ph.D. from the University of Southern California, he has driven innovations in software-defined networking (SDN), GPU virtualization, container orchestration, edge computing, Private 5G, and AI/ML systems, enabling major technology transfers across HPE business units. A recognised global thought leader, Puneet has authored 150+ papers, holds 100+ patents, co-authored IETF RFCs, and delivered keynote talks at IEEE and industry events. He is an IEEE Fellow, ACM Distinguished Scientist, and two-time Tsinghua AI 2000 Most Influential Scholar. He earned his B.Tech from IIT Delhi. His leadership continues to advance AI-powered, distributed computing and networking infrastructure worldwide. |
|
ASTRA-sim-service: A Composable Simulation Interface for AI Infrastructure Co-Design Across Workloads and Fidelity Tiers Harsh Sikhwal (Keysight) LinkedIn Abstract: Simulation plays an increasingly important role in exploring collective communication and system design trade-offs for large-scale AI workloads. However, integrating ASTRA-sim across notebooks, scripts, benchmarking environments, and applications often requires repeated configuration and custom wrappers. In this presentation, we introduce Astra-sim-service, a lightweight, schema-driven interface that provides standardized APIs and flexible deployment options for interacting with ASTRA-sim. We discuss its architecture and demonstrate how a common interface can improve reusability, simplify experimentation, and enable broader integration across simulation workflows. Bio: Harsh Sikhwal is a Senior Software Engineer at Keysight Technologies, working on AI infrastructure, system architecture, and performance engineering for large-scale AI/ML systems. He leads the development of InfraGraph and the ASTRA-sim-service, enabling reusable workflows for infrastructure modelling, simulation, and AI/ML system architecture research. His work focuses on simulation and hardware/software emulation of AI/ML workloads, collective communication, and hardware/software co-design for next-generation AI datacentres. He has contributed to SONiC, Open Traffic Generator (OTG), and network testing frameworks, and is also active in applied AI systems, including RAG- and MCP-based architectures. His interests include high-performance computing, infrastructure modelling, and AI system design. |
 |
Hespas: Multi-Fidelity Simulation of StableHLO-ML Workloads with ASTRA-sim Abubakr Nada (imec) LinkedIn Abstract: Predicting the performance of large-scale distributed machine learning (ML) workloads across multiple accelerator architectures remains a central challenge in ML system design. Existing GPU and TPU focused simulators are typically architecture-specific, while distributed training simulators rely on workload-specific analytical models or costly post-execution traces, limiting portability and cross-platform comparison. This work demonstrates MLIR's StableHLO dialect can serve as a unified workload representation for cross-architecture and cross-fidelity performance modeling of distributed ML workloads while using ASTRA-sim as a system simulator. The work establishes a StableHLO-based simulation methodology that maps a single workload representation onto multiple performance models, spanning analytical, profiling-based, and simulator-driven predictors. Using this methodology, workloads are evaluated across GPUs and TPUs without requiring access to scaled-out physical systems, enabling systematic comparison across modeling fidelities. Bio: Abubakr Nada is an R&D Engineer in Compute Systems Architecture at imec, working on architecture and performance modeling. His interests span the full stack, from applications and algorithms down to hardware microarchitecture, with current research interests focusing on optical-fabric-based rack-scale architectures, and alternative EDA tooling. He holds an M.S. in Electronics Engineering from KU Leuven |
 |
A Co-Design Framework for Heterogeneous Multi-Stage LLM Inference using ASTRA-SIM Abhimanyu Bambhaniya (Georgia Tech/InfraVana) LinkedIn Abstract: Modern LLM serving now spans multi-stage pipelines including RAG retrieval and KV cache reuse, each with distinct compute, memory, and latency demands. Inference engines expose a large configuration space with no systematic navigation methodology, and exhaustively benchmarking configurations can exceed $40K in cloud costs. Simultaneously, the hardware landscape is rapidly diversifying across AMD GPUs, TPUs, and custom ASICs, while cross-vendor prefill-decode (PD) disaggregated configurations lack unified software stacks for end-to-end evaluation today. Infravana has design an end-to-end simulation framework with astra-sim as its network simulators addressing all three challenges. We can models the full serving stack across an AI Workload Layer, a System & Software Layer, and a Hardware Layer, with pluggable accelerator models supporting cross-vendor evaluation without a unified software stack. Bio: Abhimanyu Bambhaniya is Ph.D. Candidate at Georgia Institute of Technology. His research is in HW-SW codesign of Hardware infrastructure for LLM Inference. Throughout is Ph.D. he has worked in the entire stack from LLM model training to Rack and Accelerator chip design with special focus on tools and frameworks for LLM inference modelling. He worked with at Co-design and Cloud Inference Teams at Google, Meta and Intel. His research has been adopted by internal teams at Google, Intel, Nvidia, Meta, Micron, and SK Hynix. (edited) |
  |
Enabling Memory Tiering in ASTRA-sim with Extended Chakra Traces Ulf Hanebutte (Marvell) LinkedIn Nikhil Stephen (Marvell) LinkedIn Shuting Du (Purdue University) LinkedIn Abstract: Memory has become a key bottleneck in large-scale AI systems, while most existing simulators primarily focus on compute and communication. We present ongoing work that enhances both ASTRA-sim and Chakra to support memory tiering by introducing a new memory node in the Chakra execution trace. This enables trace-driven simulation of multi-tier memory behavior, including early studies of KV cache placement and tier transitions. We share initial results to highlight the importance of memory-aware simulation and invite community feedback on this timely direction. Bio: Dr. Ulf Hanebutte is a Distinguished Engineer at Marvell with focus on HW/SW co-design within AI/ML Architecture. In this role he has contributed to multiple generations of ML inference accelerator HW and their SW stacks. More recently, his work has focused on simulation efforts that model AI/ML workloads at data-center scale. Collaborating and solving big problems together has marked his extensive career, both at the National Labs and in the private sector, with projects ranging from HPC at Exa-scale to IoT for energy efficient buildings. He holds a Ph.D. from Northwestern University and a Dipl. Ing. in Aero Space Engineering from the University of Stuttgart. Bio: Nikhil Stephen is a Senior Staff Engineer at Marvell specializing in AI/ML architecture, hardware-software co-design, and compiler stack development. He has contributed to multiple generations of ML inference accelerator platforms, with deep focus on building the software stack — particularly the compiler layers that connect AI/ML workloads to high-performance silicon. More recently, his work has shifted to data-center scale simulation infrastructure, tackling challenges across scale-up, scale-out, and memory tiering domains. He holds a Master's in Computer Engineering from North Carolina State University, with a research focus in computer architecture. Bio: Shuting Du is currently a Solutions Architecture Intern at Marvell Technology, working on memory systems and AI infrastructure modeling. She is currently pursuing the Ph.D. degree at the School of Electrical and Computer Engineering in Purdue University, specializing in memory-centric AI hardware architectures. |
  |
Enabling Energy Efficiency for Distributed Machine Learning Tanvir Ahmed Khan (Columbia University) LinkedIn Tawhid Bhuiyan (Columbia University) LinkedIn Abstract: Today, we spend a significant fraction of the world's electricity to power machine learning workloads. We aim to make these workloads energy efficient by estimating their end-to-end energy consumption. Energy estimation of machine learning workloads is challenging as they require fine-grained information for accuracy but coarse-grained abstractions for scalability. This talk will provide an overview and demonstration of how to achieve (1) accuracy by encoding fine-grained workload patterns to Chakra execution traces, and (2) scalability with ASTRA-sim's compute, memory, and networking abstractions. Bio: Tanvir Ahmed Khan is an Assistant Professor of Electrical Engineering at Columbia University. His research brings together computer architecture, compilers, and operating systems to enable efficient and trustworthy heterogeneous processing. Bridging hardware and software, his research appears in venues like ISCA, MICRO, ASPLOS, OSDI, PLDI, Oakland, HPCA, FAST, and EuroSys. His work has also been recognized with the 2024 ACM SIGARCH/IEEE CS TCCA Outstanding Dissertation Award, IEEE Micro Top Picks 2023 distinction, and MICRO 2022 Best Paper Award. Bio: Tawhid Bhuiyan is a 2nd year PhD student at Columbia University. His research focuses on performance and energy efficiency for data center applications. He is currently seeking a summer internship in industry. |
 |
Modeling Multi-tenant Scheduling in ML Clusters using Astra-sim Shawn Chen (CMU) LinkedIn Abstract: Multi-tenant ML clusters suffer from fragmentation, topology constraints, and network contention when jobs with different parallelism shapes share the same accelerator fabric, making scheduling difficult because improving utilization can directly hurt job runtime. This problem is especially prominent on reconfigurable torus-based systems such as TPU clusters where the network topology is direct-connect and can change over time. We propose extensions to ASTRA-sim with runtime-reconfigurable network backend and multi-tenant job trace support, including support for job arrivals, admission and placement policies, idle nodes, and logical-to-physical rank translation. With these extensions, ASTRA-sim can quantify scheduling tradeoffs across policies such as FIFO, shortest-job-first, backfilling, FirstFit, and random placement, showing how scheduling choices substantially shift job completion time distributions and expose the tension between utilization, contention, and tail latency. Bio: Shawn Shuoshuo Chen is a final-year PhD student in Computer Science at Carnegie Mellon University, co-advised by Srinivasan Seshan and Peter Steenkiste. His research focuses on building scalable, cost- and power-efficient interconnection networks for data centers and clouds. Some of his work has already been deployed in production, including Google's Jupiter networks and Microsoft's MAIA cluster. He has also made open source contributions to the Open Compute Project. |
Additional Resources
ASTRA-sim 3.0 Paper
William Won, Jinsun Yoo, Tuan Ta, Moumita Dey, Andy Balogh, Pradosh Datta, Furkan Eris, Conor Green, Winston Liu, Changhai Man, Kingshuk Mandal, Amos Rai, Vinay Ramakrishnaiah, Ruchi Shah, David Sidler, Harsh Sikhwal, Hanjiang Wu, Tushar Krishna, and Bradford M. Beckmann, “ASTRA-sim 3.0: Next-Level Distributed Machine Learning Simulations via High-Fidelity GPU and Infrastructure Modeling,” in arXiv:2606.10440 [cs.DC], 2026.
ASTRA-sim 2.0 Paper
William Won, Taekyung Heo, Saeed Rashidi, Srinivas Sridharan, Sudarshan Srinivasan, and Tushar Krishna, “ASTRA-sim2.0: Modeling Hierarchical Networks and Disaggregated Systems for Large-model Training at Scale,” in Proc. of the IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2023.
Chakra Paper
Srinivas Sridharan, Andy Balogh, Bradford M. Beckmann, Brian Coutinho, Louis Feng, Sheng Fu, Sanshan Gao, Mehryar Garakani, Taekyung Heo, David Kanter, Josh Ladd, Ziwei Li, Winston Liu, Changhai Man, Dan Mihailescu, Spandan More, Joongun Park, Ashwin Ramachandran, Vinay Ramakrishnaiah, Saeed Rashidi, Vijay Reddi, Puneet Sharma, Phio Tian, William Won, Hanjiang Wu, Huan Xu, Jinsun Yoo, and Tushar Krishna, “MLCommons Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces,” in Proc. of the 9th Conference on Machine Learning and Systems (MLSys), 2026.