Validation on GPU Systems - NCCL over HGX-H100 Systems
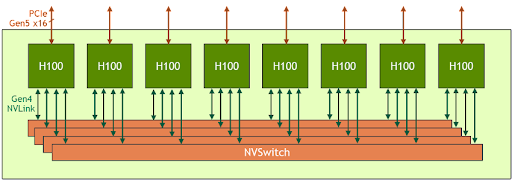
HGX-H100 Topology
Senario - 1: 2-GPUs All-Reduce
Hardware Setup
2 H100 GPUs connected in switch, over 4 NVSwitches
Each GPU has bidirectional BW of 900 GB/s
NCCL Ring Algorithm
ASTRA-Sim setup
Modelled with the ASTRA-Sim Analytical Backend
Switch Network Topology
Collectives run
All-Reduce
Reduction operation - Sum
Results
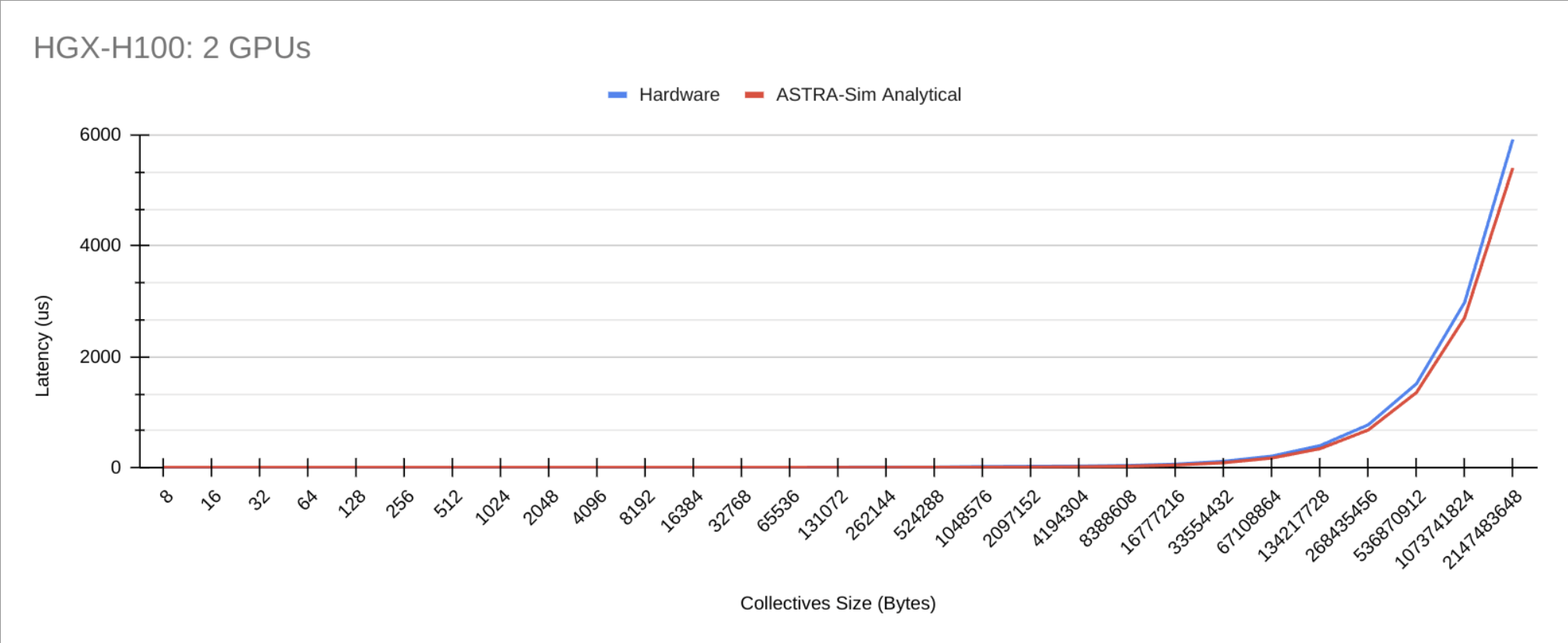
Geomean error rate = 20.63%
Senario - 2: 4-GPUs All-Reduce
Hardware Setup
4 H100 GPUs connected in switch, over 4 NVSwitches
Each GPU has bidirectional BW of 900 GB/s
NCCL Ring Algorithm
ASTRA-Sim setup
Modelled with the ASTRA-Sim Analytical Backend
Switch Network Topology
Collectives run
All-Reduce
Reduction operation - Sum
Results
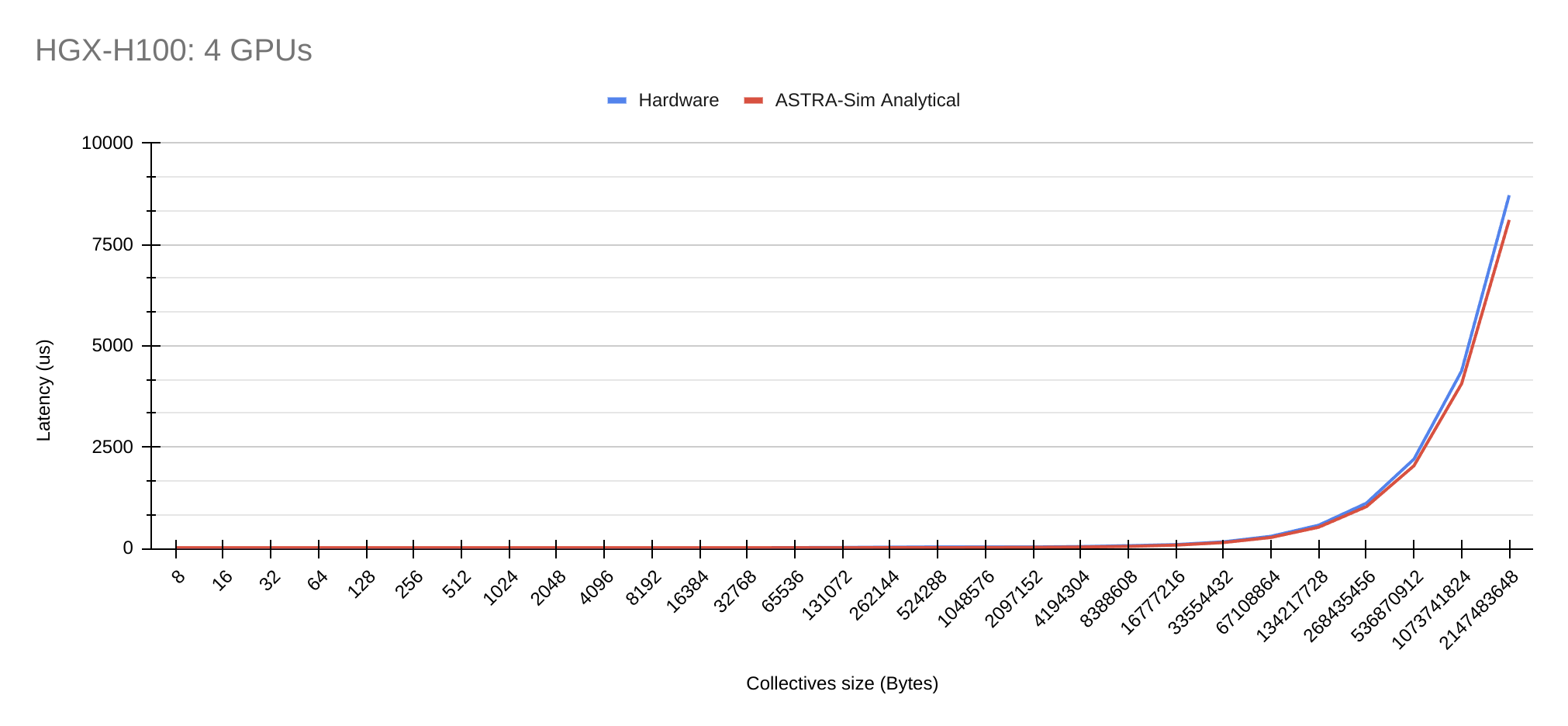
Geomean error rate = 12.01%
Senario - 3: 8-GPUs All-Reduce
Hardware Setup
8 H100 GPUs connected in switch, over 4 NVSwitches
Each GPU has bidirectional BW of 900 GB/s
NCCL Ring Algorithm
ASTRA-Sim setup
Modelled with the ASTRA-Sim Analytical Backend
Switch Network Topology
Collectives run
All-Reduce
Reduction operation - Sum
Results
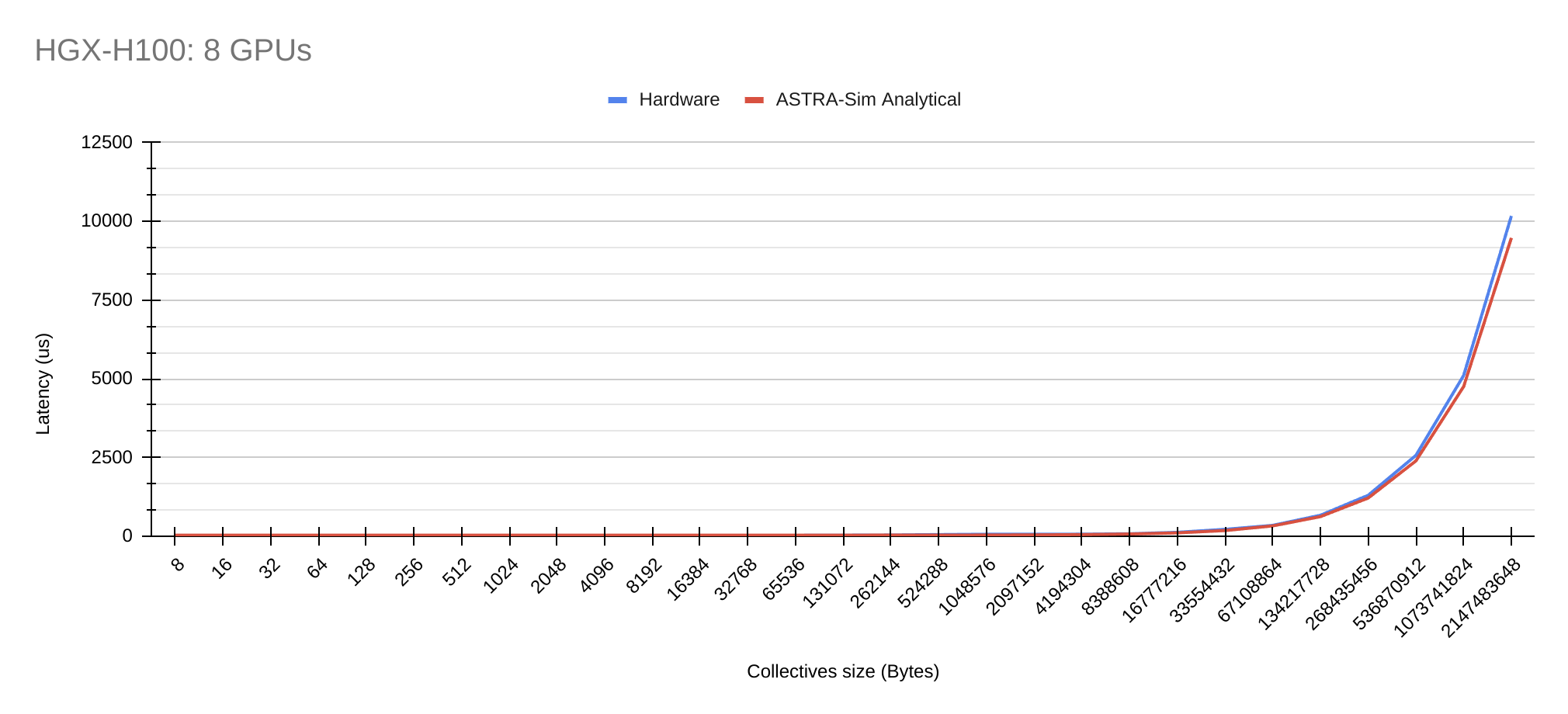
Geomean error rate = 9.69%
Recommended practices
Emperically extract warm up latency by running smaller collectives
Emperically extract practical link latency by first running smaller collectives and varying number of NPUs/GPUs
It is observed that the maximum achieved BW is 741.34 GB/s (bidirectional).
Strictly enforce NCCL to use only Ring Algorithm. NCCL switches from Ring to Tree algorithm with respect to Collective sizes. We observe this to be suboptimal, atleast for this topology, hardware and configuration.